Superpapers: Turning AI into a Research Partner
A Claude Code plugin for empirical academic research — from brainstorm to journal submission
There is a quiet crisis underway in academic research, and the honest version of it is embarrassing to admit out loud. We are all using AI now. Maybe even this post is AI — do you see the em-dashes? We paste regression output into a chat window and ask what it means. We draft paragraphs, outline sections, translate idioms, debug stubborn scripts. And none of it is written down. The conversation scrolls off the screen, the decision moves into the paper, and six months later, when a referee asks why did you choose this specification?, there is no trail. Just a vague memory of a chat that was almost certainly persuasive at the time.
The issue is not that AI is bad for research. It is that the way we currently use it is not research. It is improvisation with very articulate assistance. Every choice a paper depends on — the identification strategy, the observations we excluded, the controls we settled on, the robustness checks we ran and the ones we abandoned — becomes a private, undocumented conversation. Replication, already hard, gets harder. And authorship, already fuzzy at the edges, gets fuzzier.
I built superpapers to tackle both sides of the problem: to make AI-assisted research reproducible, and to keep the AI from quietly making consequential decisions on its own. The plugin turns Claude into a Socratic research partner that refuses to move past a decision without surfacing it, pushes back on assumptions, and keeps the whole exchange on the record. In the process it grew into a pipeline that spans every stage of producing a research article, with one non-negotiable promise: the finished paper is an honest record of what was tried, what failed, and what we finally settled on.
What is Superpapers
superpapers is a Claude Code plugin that structures human–AI interaction around the full lifecycle of an empirical academic paper: brainstorming the question, planning the design, executing the analysis, reviewing the manuscript, and submitting to a journal. It is directly inspired by superpowers, which brings the same kind of discipline to software engineering. The adaptation to research was the interesting part: research is not code, but the pipeline metaphor holds remarkably well once you take reproducibility seriously.
Two links to keep handy while reading:
- Interactive live presentation: twenty-four screenshots from a real Claude Code session, narrated end-to-end
- GitHub repository: source, templates, and installation docs
The short version of the idea is this: instead of one long unstructured conversation, you move through five stages, each of which produces an artifact that outlives the chat window. Each stage has a Socratic guardrail that pushes back, asks the uncomfortable questions, and refuses to let you skip ahead. Every result the paper depends on is tied to a script. Every script is tied to raw data. Nothing floats.
Getting started
Installation is two lines inside Claude Code:
/plugin marketplace add regisely/superpapers
/plugin install superpapers
After that, you can simply start talking. Tell Claude what you want to research and the relevant skills activate based on context. To pre-populate project settings like target paper language, preferred code stack, significance convention, or custom rules, run /superpapers:init at any point, before or after starting the brainstorm. It writes a CLAUDE.superpapers.md file at the paper’s root that every skill reads on activation, and the file stays editable at any time, by you or by Claude.
A note on practicality: the plugin works with any Claude subscription, but building a publishable paper is genuinely token-intensive. I recommend the Max plan with the most capable available model and a large context window (1M tokens when available). And always review everything the pipeline produces before submitting anywhere, and check your target journal’s AI-use policy. The plugin is a research partner, not a ghostwriter.
A real session, narrated
The plugin ships with a full walkthrough, and the walkthrough is not a toy. It is an actual Claude Code session that produced a working paper, and the reason it is worth watching is that the first identification strategy fails its diagnostics, and the design has to pivot mid-analysis.
The session starts with a concrete question: does credit expansion cause productivity growth, and does the composition of credit matter? The brainstorm phase locks down the question, identifies the data (a cross-country panel of 43 countries from 1996 to 2019, combining BIS credit statistics with Penn World Table TFP), and proposes a first identification strategy: a shift-share instrumental variable built from countries’ pre-period exposure to foreign banks, interacted with global bank lending shocks. The plan phase expands this into phases. The execute phase collects the data, prepares it, runs exploratory diagnostics, and estimates the main model.
And then estimation goes sideways. The shift-share instrument fails to predict domestic credit. The first-stage F-statistic sits well below ten across every specification. A lesser workflow would fudge this: maybe add a control, maybe weaken the claim, maybe quietly pretend the diagnostic never ran. This workflow does something different: it surfaces the failure, names it explicitly, and proposes a structured pivot to system GMM with internal instruments. The pivot is not a shortcut; it is a design change with its own justification, and the failed Bartik attempt itself becomes informative: the absence of a credit supply channel from foreign bank exposure suggests domestic credit is demand-driven. The plan is updated. The execution resumes. The paper gets written around what the data actually supports, not around what we originally hoped it would.
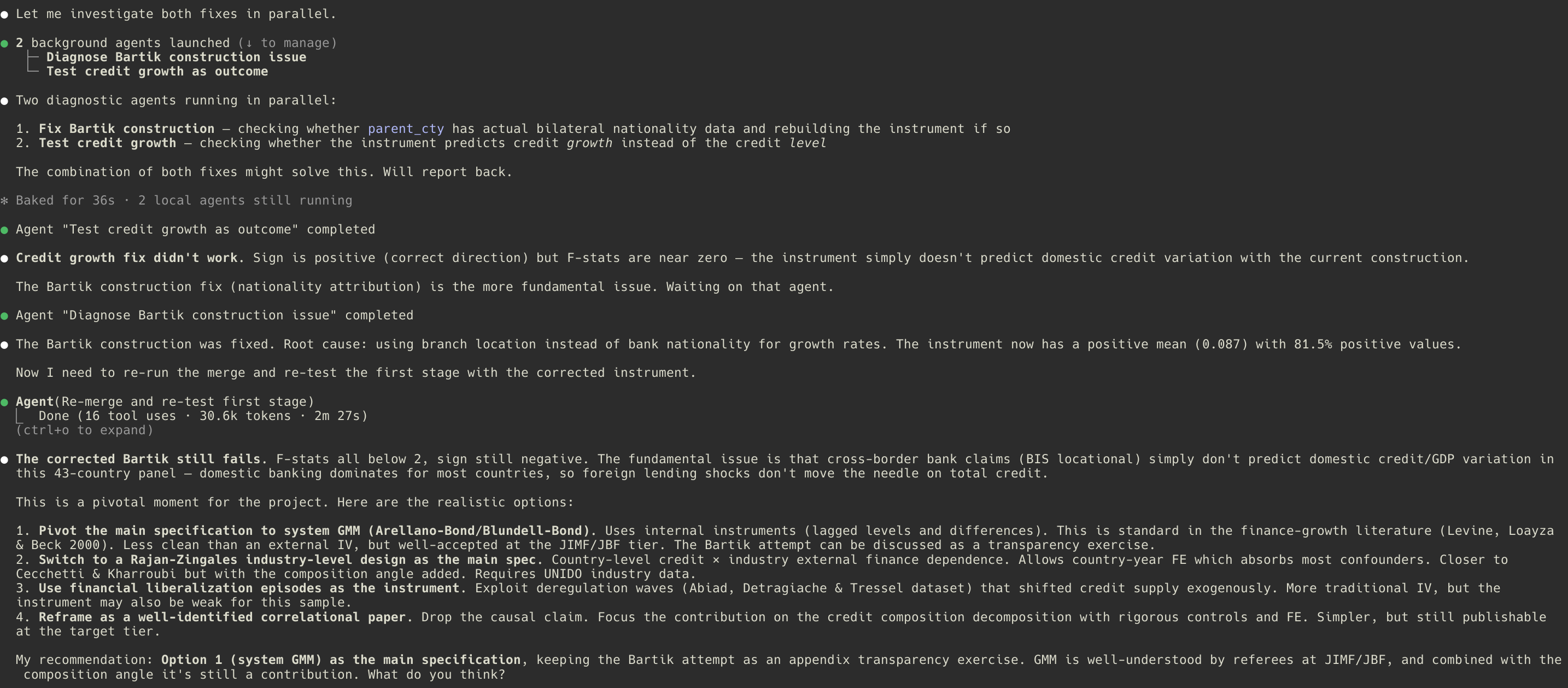
- The pivot. When the first identification strategy fails its diagnostics, the plugin surfaces the problem and proposes a structured alternative, rather than forcing a weak result. (Click to see all session screenshots on GitHub.)

That single beat (the pivot) is what convinced me this approach was worth formalizing. Most of the damage AI does to research right now comes from how seamlessly it can rationalize a bad result. A structured workflow that forces you to confront failed diagnostics, and then gives you a disciplined way to respond to them, is closer to what we actually want.
Two example papers
To make this concrete, two example manuscripts produced with the plugin are available:
- Credit and productivity (the paper produced by the real session walked through above)
- Monetary pass-through
Both are full papers (introduction, data, methods, results, robustness, references) produced end-to-end through the workflow. They are not showroom pieces; they are what the pipeline outputs when you follow it.
Field-agnostic by design
Although I am an economist and the examples lean on econometrics, the plugin is not an economics plugin. It has been built deliberately field-agnostic. The same pipeline applies to political science (causal identification in observational panels), epidemiology (exposure–outcome studies), public health (policy evaluation), environmental science (remote-sensing analyses), quantitative psychology (experimental designs), and sociology (demographic surveys). The skills route methods, data sources, and journal suggestions based on the research question, not a hard-coded list.
Under the hood: five stages, one audit trail
The pipeline itself is easy to describe:
Brainstorm ──► Plan ──► Execute ──► Review ──► Submit
│ │ │ │ │
▼ ▼ ▼ ▼ ▼
design spec phased plan scripts + tables audit report journal package
Each arrow is a review checkpoint. You approve each artifact before moving forward, and the approval has to come from you, not the model. The design spec names the question, the identification strategy, and the contribution. The plan breaks the spec into phased tasks (collection, preparation, analysis, robustness, writing, submission) with explicit verification criteria. Execution dispatches subagents that do the work one phase at a time, with two-stage review at every phase boundary. The review stage audits the complete draft — text, code, tables, figures, results, citations, and reproducibility — in a single pass and writes a consolidated report to docs/superpapers/review/; when the plan includes a submission phase, this audit blocks completion until it returns a go verdict. Submission formats the manuscript to a specific journal’s instructions and verifies the checklist.
The important consequence is that at any point in the project, you can hand somebody the artifacts (spec, plan, code, outputs, paper) and they can reproduce the entire trajectory, including the dead ends.
The guardrail: replication-driven research
The plugin has one non-negotiable rule, and everything else is designed around it.
This is the analogue of test-driven development in software, transposed to research. The replication-driven-research skill acts as a standing policy that every other skill respects. Manual copy-pasting of regression output into a LaTeX table is blocked. Hard-coded numbers are blocked. Screenshots of output as “data” are blocked. If a coefficient appears in the paper, the pipeline must know where it came from and how to regenerate it.
This one rule is what turns Claude-assisted research from a chat log into a repository.
Writing that doesn’t sound like AI
Reproducibility is only half the story. The other half is the prose. A newer skill called paper-writing covers drafting, rewriting, reviewing, and auditing any section of the paper (Abstract, Introduction, Methods, Results, Conclusion), as well as specialized outputs like job market papers, grant proposals, policy briefs, and referee responses. It encodes section-specific formulas (what an introduction is supposed to do in four moves, what a results section is supposed to avoid), style rules, and a hundred-point review rubric that the plugin runs against its own output. It also explicitly flags the AI giveaways (including, incidentally, the em-dashes we worked so hard to cull from this very post).
You can invoke it directly with /superpapers:write-paper whenever you are drafting or revising prose, or let the orchestration route to it inside the broader pipeline.
When the draft is complete, its sibling skill paper-review takes over: a holistic pre-submission audit that cross-cuts text, code, tables, figures, results, citations, and reproducibility in one pass, invoked with /superpapers:paper-review. The audit is not advisory. It produces a severity-ranked report with a go/no-go verdict, backed by deterministic check scripts that catch the defects LLMs love to ship — tables overflowing the margins, raw code identifiers leaking into labels, citation styles that do not match the journal — and the audit-and-remediate cycle repeats until the verdict is go. It also works standalone: you can point it at any paper folder, including one written entirely outside the plugin.
The sixteen skills
Under the hood, the plugin is a set of skills that activate based on the conversation. They are organized by role:
| Skill | Role | Purpose |
|---|---|---|
brainstorm |
Orchestration | Socratic exploration of a research idea; produces a design spec |
write-plan |
Orchestration | Translates an approved spec into a phased execution plan |
execute-plan |
Orchestration | Runs the plan phase by phase with subagents and two-stage review |
academic-baseline |
Foundation | Non-negotiable principles that govern all other skills |
replication-driven-research |
Foundation | End-to-end reproducibility guardrail |
compile-latex |
Foundation | Multi-pass LaTeX compilation with engine and bib detection |
literature-search |
Pipeline | Web-verified search across academic databases |
citation-management |
Pipeline | BibTeX management via CrossRef API (no Zotero needed) |
data-collection |
Pipeline | Data discovery, respectful collection, manifest documentation |
statistical-modeling |
Analysis | Open-ended modeling with method-family references |
tables-and-figures |
Analysis | Publication-quality LaTeX tables and vector PDF figures |
robustness-checks |
Analysis | Design-appropriate canonical robustness checks |
paper-writing |
Writing | Section formulas, style rules, AI-pattern avoidance, 100-point review rubric |
paper-review |
Review | Pre-submission holistic audit across text, code, tables, figures, results, citations, and reproducibility; works standalone on external papers |
journal-selection |
Submission | Field-agnostic journal matching with tier strategy |
journal-guidelines |
Submission | Parses author instructions and builds a submission checklist |
You do not call these directly. You describe what you are working on, and the orchestration layer routes to the right skill. The five slash commands (/superpapers:brainstorm, /superpapers:write-plan, /superpapers:execute-plan, /superpapers:write-paper, /superpapers:paper-review) exist for when you want to enter the pipeline at a specific stage.
Closing
The broader bet behind superpapers is that AI assistance in academic research does not have to compromise reproducibility or authorship. The opposite, in fact: a well-structured pipeline makes both better than the status quo, because it forces us to document choices that, left to ourselves, we tend to leave implicit. If you try the plugin, I would love to hear what works, what breaks, and what you wish it did. The best research tools get better the more researchers use them honestly.