Superpapers: Transformando a IA em uma Parceira de Pesquisa
Um plugin do Claude Code para pesquisa acadêmica empírica — do brainstorm à submissão em periódico
Há uma crise silenciosa acontecendo na pesquisa acadêmica, e a versão honesta dela é constrangedora de admitir em voz alta. Todos nós estamos usando IA agora. Talvez até este post seja IA — você percebe os travessões? Colamos output de regressão numa janela de chat e perguntamos o que aquilo significa. Redigimos parágrafos, esboçamos seções, traduzimos idiomatismos, depuramos scripts teimosos. E nada disso fica registrado. A conversa rola para fora da tela, a decisão entra no paper, e seis meses depois, quando um parecerista pergunta por que você escolheu essa especificação?, não há rastro. Só uma lembrança vaga de um chat que era quase certamente persuasivo na hora.
O problema não é que a IA seja ruim para pesquisa. É que a forma como a usamos hoje não é pesquisa. É improvisação com assistência muito articulada. Toda escolha de que um paper depende — a estratégia de identificação, as observações que excluímos, os controles em que paramos, os testes de robustez que rodamos e os que abandonamos — vira uma conversa privada e não documentada. A replicação, já difícil, fica mais difícil. E a autoria, já nebulosa nas bordas, fica mais nebulosa.
Construí o superpapers para atacar os dois lados do problema: tornar a pesquisa assistida por IA reprodutível, e evitar que a IA tome decisões consequentes silenciosamente por conta própria. O plugin transforma o Claude em uma parceira de pesquisa socrática que se recusa a seguir adiante com uma decisão sem trazê-la à tona, questiona premissas e mantém toda a interação registrada. Nesse processo, ele cresceu em um pipeline que cobre cada etapa da produção de um artigo científico, com uma promessa inegociável: o paper finalizado é um registro honesto do que foi tentado, do que falhou e do que decidimos no final.
O que é o Superpapers
superpapers é um plugin do Claude Code que estrutura a interação humano–IA em torno do ciclo completo de um artigo acadêmico empírico: brainstorm da pergunta, planejamento do desenho, execução da análise, revisão do manuscrito e submissão para um periódico. É diretamente inspirado pelo superpowers, que traz o mesmo tipo de disciplina para engenharia de software. A adaptação para pesquisa foi a parte interessante: pesquisa não é código, mas a metáfora do pipeline se sustenta notavelmente bem quando reprodutibilidade é levada a sério.
Dois links para ter à mão durante a leitura:
- Apresentação interativa: vinte e quatro screenshots de uma sessão real do Claude Code, narrados de ponta a ponta
- Repositório no GitHub: código-fonte, templates e instruções de instalação
A versão curta da ideia é esta: em vez de uma longa conversa sem estrutura, você percorre cinco fases, cada uma produzindo um artefato que sobrevive à janela do chat. Cada fase tem uma barreira socrática que rebate, faz as perguntas desconfortáveis e se recusa a deixar você pular etapas. Todo resultado de que o paper depende está amarrado a um script. Todo script está amarrado aos dados brutos. Nada flutua solto.
Primeiros passos
A instalação é de duas linhas dentro do Claude Code:
/plugin marketplace add regisely/superpapers
/plugin install superpapers
Depois disso, basta começar a conversar. Diga ao Claude o que você quer pesquisar e as skills relevantes são ativadas conforme o contexto. Para pré-configurar preferências do projeto como idioma do paper, stack de código preferida, convenção de significância ou regras customizadas, rode /superpapers:init a qualquer momento, antes ou depois de iniciar o brainstorm. O comando escreve um arquivo CLAUDE.superpapers.md na raiz do projeto que toda skill lê ao ser ativada, e o arquivo permanece editável a qualquer momento, por você ou pelo próprio Claude.
Uma nota prática: o plugin funciona com qualquer assinatura do Claude, mas construir um paper publicável é genuinamente intensivo em tokens. Recomendo o plano Max com o modelo mais capaz disponível e uma janela de contexto ampla (1M de tokens quando disponível). E sempre revise tudo o que o pipeline produz antes de submeter a qualquer lugar, e verifique a política de uso de IA do periódico alvo. Isso não é negociável. O plugin é uma parceira de pesquisa, não um ghostwriter.
Uma sessão real, narrada
O plugin vem com um walkthrough completo, e o walkthrough não é um brinquedo. É uma sessão real do Claude Code que produziu um paper funcional, e o motivo para assistir é que a primeira estratégia de identificação falha no diagnóstico, e o desenho precisa pivotar no meio da análise.
A sessão começa com uma pergunta concreta: a expansão de crédito causa crescimento de produtividade, e a composição do crédito importa? A fase de brainstorm fixa a pergunta, identifica os dados (um painel de 43 países entre 1996 e 2019, combinando estatísticas de crédito do BIS com a TFP da Penn World Table) e propõe uma primeira estratégia de identificação: uma variável instrumental shift-share construída a partir da exposição pré-período dos países a bancos estrangeiros, interagida com choques globais de empréstimo bancário. A fase de plano expande isso em etapas. A fase de execução coleta os dados, prepara, roda diagnósticos exploratórios e estima o modelo principal.
E então a estimação azeda. O instrumento shift-share falha em prever o crédito doméstico. A estatística F do primeiro estágio fica bem abaixo de dez em toda especificação. Um fluxo de trabalho inferior daria um jeitinho: talvez adicionar um controle, talvez enfraquecer a afirmação, talvez fingir discretamente que o diagnóstico nunca rodou. Este fluxo faz algo diferente: traz a falha à tona, a nomeia explicitamente e propõe um pivô estruturado para system GMM com instrumentos internos. O pivô não é um atalho; é uma mudança de desenho com sua própria justificativa, e a tentativa fracassada do Bartik em si vira informativa: a ausência de um canal de oferta de crédito a partir da exposição a bancos estrangeiros sugere que o crédito doméstico é puxado pela demanda. O plano é atualizado. A execução retoma. O paper é escrito em torno do que os dados de fato sustentam, não do que originalmente esperávamos que sustentassem.
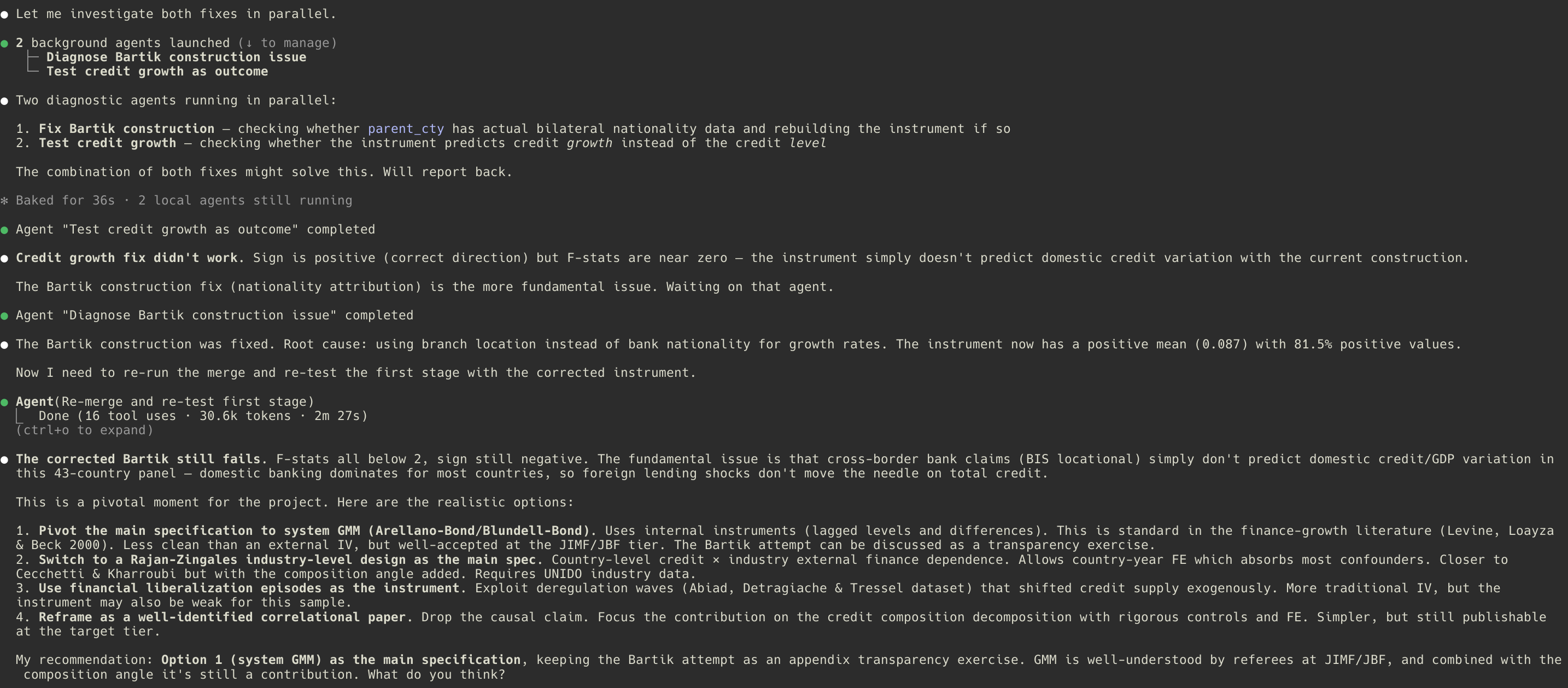
- O pivô. Quando a primeira estratégia de identificação falha no diagnóstico, o plugin traz o problema à tona e propõe uma alternativa estruturada, em vez de forçar um resultado fraco. (Clique para ver todos os screenshots da sessão no GitHub.)

Esse momento específico (o pivô) é o que me convenceu de que a abordagem valia a pena ser formalizada. A maior parte do dano que a IA faz à pesquisa hoje vem da facilidade com que ela racionaliza um resultado ruim. Um fluxo de trabalho estruturado que te força a encarar diagnósticos que falharam, e depois te dá uma forma disciplinada de responder a eles, está mais próximo do que de fato queremos.
Dois papers de exemplo
Para tornar isso concreto, dois manuscritos de exemplo produzidos com o plugin estão disponíveis:
- Credit and productivity (o paper produzido pela sessão real narrada acima)
- Monetary pass-through
Ambos são papers completos (introdução, dados, métodos, resultados, robustez, referências) produzidos ponta a ponta pelo fluxo. Não são peças de vitrine; são o que o pipeline entrega quando ele é seguido.
Agnóstico a área de pesquisa
Embora eu seja economista e os exemplos pendam para econometria, o plugin não é um plugin de economia. Ele foi construído deliberadamente agnóstico a área de pesquisa. O mesmo pipeline se aplica a ciência política (identificação causal em painéis observacionais), epidemiologia (estudos de exposição-desfecho), saúde pública (avaliação de políticas), ciências ambientais (análises com sensoriamento remoto), psicologia quantitativa (desenhos experimentais) e sociologia (pesquisas demográficas). As skills roteiam métodos, fontes de dados e sugestões de periódico a partir da pergunta de pesquisa, não de uma lista fixa.
Se sua pesquisa gera números a partir de dados usando código, o superpapers tem opiniões sobre como fazer isso bem.
Nos bastidores: cinco fases, uma trilha auditável
O pipeline em si é fácil de descrever:
Brainstorm ──► Plano ──► Execução ──► Revisão ──► Submissão
│ │ │ │ │
▼ ▼ ▼ ▼ ▼
spec de design plano em fases scripts+tabelas relatório de pacote final
auditoria
Cada seta é um ponto de revisão. Você aprova cada artefato antes de avançar, e a aprovação precisa vir de você, não do modelo. A spec de design nomeia a pergunta, a estratégia de identificação e a contribuição. O plano decompõe a spec em tarefas faseadas (coleta, preparação, análise, robustez, escrita, submissão) com critérios de verificação explícitos. A execução despacha subagentes que fazem o trabalho uma fase de cada vez, com revisão em duas etapas em cada fronteira entre fases. A fase de revisão audita o rascunho completo — texto, código, tabelas, figuras, resultados, citações e reprodutibilidade — em uma única passada e escreve um relatório consolidado em docs/superpapers/review/; quando o plano inclui uma fase de submissão, essa auditoria bloqueia a conclusão até retornar um veredito go. A submissão formata o manuscrito de acordo com as instruções de um periódico específico e verifica o checklist.
A consequência importante é que em qualquer ponto do projeto você pode entregar a alguém os artefatos (spec, plano, código, outputs, paper) e essa pessoa consegue reproduzir toda a trajetória, inclusive os becos sem saída.
A barreira: pesquisa guiada por replicação
O plugin tem uma regra inegociável, e todo o resto é projetado em torno dela.
Este é o análogo do test-driven development em software, transposto para pesquisa. A skill replication-driven-research atua como política padrão que todas as outras skills respeitam. Copiar e colar manualmente output de regressão em uma tabela LaTeX é bloqueado. Números hard-coded são bloqueados. Screenshots de output como se fossem “dados” são bloqueados. Se um coeficiente aparece no paper, o pipeline precisa saber de onde ele veio e como regenerá-lo.
Essa única regra é o que transforma pesquisa assistida por Claude de um log de chat em um repositório.
Escrita que não parece de IA
Reprodutibilidade é só metade da história. A outra metade é a prosa. Uma skill mais recente, chamada paper-writing, cobre redigir, reescrever, revisar e auditar qualquer seção do paper (Abstract, Introdução, Métodos, Resultados, Conclusão), bem como produções especializadas como job market papers, propostas de financiamento, policy briefs e cartas de resposta a pareceristas. Ela codifica fórmulas por seção (o que uma introdução deve fazer em quatro movimentos, o que uma seção de resultados deve evitar), regras de estilo e uma rubrica de revisão de cem pontos que o plugin roda contra sua própria saída. Ela também aponta explicitamente os sinais típicos de IA (incluindo, a propósito, os travessões que tanto tentamos reduzir neste próprio post).
Você pode invocá-la diretamente com /superpapers:write-paper sempre que estiver redigindo ou revisando prosa, ou deixar a orquestração rotear para ela dentro do pipeline mais amplo.
Quando o rascunho está completo, a skill irmã paper-review assume: uma auditoria holística pré-submissão que cruza texto, código, tabelas, figuras, resultados, citações e reprodutibilidade em uma única passada, invocada com /superpapers:paper-review. A auditoria não é consultiva. Ela produz um relatório com achados classificados por severidade e um veredito go/no-go, apoiado em scripts de verificação determinísticos que pegam os defeitos que LLMs adoram entregar — tabelas estourando as margens, identificadores de código vazando para os rótulos, estilos de citação que não batem com o periódico — e o ciclo de auditoria e correção se repete até o veredito ser go. Ela também funciona de forma independente: você pode apontá-la para qualquer pasta de paper, inclusive um escrito inteiramente fora do plugin.
As dezesseis skills
Por baixo do capô, o plugin é um conjunto de skills que se ativam conforme a conversa. Elas estão organizadas por função:
| Skill | Função | Propósito |
|---|---|---|
brainstorm |
Orquestração | Exploração socrática de uma ideia de pesquisa; produz uma spec de design |
write-plan |
Orquestração | Traduz uma spec aprovada em um plano de execução faseado |
execute-plan |
Orquestração | Roda o plano fase por fase com subagentes e revisão em duas etapas |
academic-baseline |
Fundação | Princípios inegociáveis que regem todas as outras skills |
replication-driven-research |
Fundação | Barreira de reprodutibilidade ponta a ponta |
compile-latex |
Fundação | Compilação LaTeX multi-passos com detecção de engine e bib |
literature-search |
Pipeline | Busca verificada em bases acadêmicas |
citation-management |
Pipeline | Gerenciamento BibTeX via API do CrossRef (sem precisar do Zotero) |
data-collection |
Pipeline | Descoberta de dados, coleta respeitosa e documentação em manifesto |
statistical-modeling |
Análise | Modelagem aberta com referências a famílias de métodos |
tables-and-figures |
Análise | Tabelas LaTeX e figuras PDF vetoriais com qualidade de publicação |
robustness-checks |
Análise | Testes de robustez canônicos apropriados ao desenho |
paper-writing |
Escrita | Fórmulas por seção, regras de estilo, prevenção de padrões de IA, rubrica de 100 pontos |
paper-review |
Revisão | Auditoria holística pré-submissão cobrindo texto, código, tabelas, figuras, resultados, citações e reprodutibilidade; funciona de forma independente em papers externos |
journal-selection |
Submissão | Seleção de periódicos agnóstica a área, com estratégia por tier |
journal-guidelines |
Submissão | Lê instruções aos autores e monta o checklist de submissão |
Você não chama essas skills diretamente. Você descreve no que está trabalhando, e a camada de orquestração roteia para a skill certa. Os cinco slash commands (/superpapers:brainstorm, /superpapers:write-plan, /superpapers:execute-plan, /superpapers:write-paper, /superpapers:paper-review) existem para quando você quer entrar no pipeline em uma etapa específica.
Fechamento
A aposta mais ampla por trás do superpapers é que a assistência de IA na pesquisa acadêmica não precisa comprometer reprodutibilidade ou autoria. Pelo contrário: um pipeline bem estruturado deixa as duas melhores do que o status quo, porque força a documentar escolhas que, deixadas por nossa conta, tendemos a deixar implícitas. Se você experimentar o plugin, adoraria ouvir o que funciona, o que quebra e o que você gostaria que ele fizesse. As melhores ferramentas de pesquisa melhoram conforme mais pesquisadores as usam com honestidade.